全結合層の問題点は、データの形状が無視されてしまうこと。
例えば、入力データが MNIST データセットのような画像である場合、データは縦・横・チャンネル方向の3次元の形状を持つ。 それにもかかわらず、全結合層に入力するときは3次元のデータを1次元のデータにする必要がある。具体的には、1チャンネル、縦28ピクセル、横28ピクセルの形状を1列に並べた784個のデータとして全結合層に入力していた。
画像は3次元の形状(ほぼ2次元だが)であり、この形状には重要な空間的情報が含まれるはずである。空間的に近いピクセルは似たような値になったり、RBGの各チャンネル間にはそれぞれ密接な関連性があったり、距離の離れたピクセル同士はあまり関わりがなかったり。
これを解決するのが 畳み込み層 (Convolution Layer)である。
全結合層では 次元ベクトルに対し 個のニューロンが存在しており、各ニューロンで 次元ベクトルの各要素に対する重みが存在している。すなわち、入力 に対し の重みが存在する。
一方で、 CNN ではフィルターの 個の重みを 個の位置で共有する。すなわち、入力 に対し、 の重みが存在する。
これを全結合層で実現すると、 の重みとなる。
から、CNN のパラメータ数は全結合層のパラメータ数よりもずっと少なくなる。
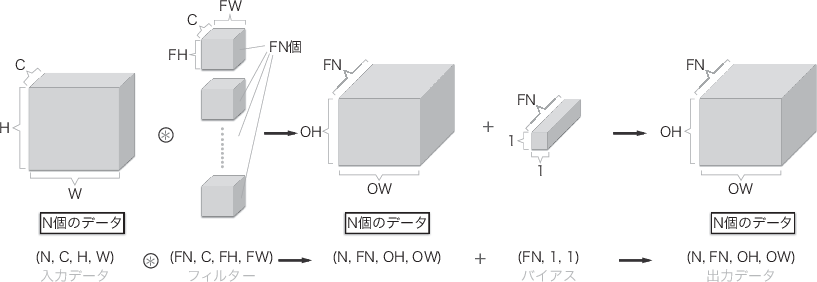 fig07_13.png
(引用『ゼロから作るDeep Learning ー Pythonで学ぶディープラーニングの理論と実装』)
fig07_13.png
(引用『ゼロから作るDeep Learning ー Pythonで学ぶディープラーニングの理論と実装』)
理論上は、 CNN によるパラメータ探索範囲は全結合層のパラメータ探索範囲の部分集合 になる。
すなわち、CNN の形状で最適な重みが見つかった場合、全結合層においてもそれは実現可能な重みとして存在する。ただ、CNN のフィルターを共有するという賢い仮定(逆に表現力を抑えるある種の制約のようなものとも言えそうなモノ)が導入されたことにより、より効率的にパラメータ探索ができるようになるというわけである。
画像という対象に対して、
という事前知識を構造に組み込んだ、という見方ができる。
制約というより、賢い仮定を入れたことで効率よく学習できるようになったイメージを持つと良い。
フィルターが を持つのは、例えば Red の時と Green の時と Blue の時でフィルターを使い分けたいから。このため、 の3次元は持つことになる。
出力チャンネル、これは フィルターの出力結果をベクトルとして持ちたいから。これは全結合層でm次元ベクトルにするのと同様。
全結合層:
CNN:
